Google Good GovernanceTM(=Topic Maps)
Nederland blijkt niet ‘rampenproof’, ondanks de 200.000 professionals ‘voor het veilige gevoel’. Probleem komt deels door de chaos van onbetrouwbare data, verspreid over tienduizenden databases die verwerkt wordt door nauwelijks communicerende applicaties. Automatiseerders bieden complexe ‘oplossingen’. Echter met standaard zoektechnologie en Topic Maps kan eenvoudig op grote schaal informatie georganieerd en kennis geaggregeerd worden.
In 2006 hebben circa 400 ambtenaren van alle ministeries een kritisch onderzoek gedaan naar de mate van ‘rampenproof’ zijn van ons land. De uitkomst: dat zijn we niet.
Het was niet de bedoeling om de resultaten van het onderzoek openbaar te maken, maar na een beroep op de wet Openbaarheid van Bestuur heeft de NOS de rapporten toch in handen gekregen. Én ze vervolgens 20 augustus jl. gepubliceerd op hun site www.nosjournaal.nl .
Het zijn nogal wat rapporten, in totaal 55,5 megabyte. 20 rapporten vanuit evenveel verschillende invalshoeken, kennisgebieden. De onderwerpen terrorisme en georganiseerde criminaliteit nemen alleen al 9 rapporten, invalshoeken in beslag. De kranten hadden onmiddellijk hun mening klaar: ‘Laksheid en slechte samenwerking troef’, zo melde de krant van wakker Nederland de volgende dag.
Een snel oordeel en wat hard. Als je iemand slecht gereedschap geeft, dan moet je ook niet raar staan kijken als die een slecht product aflevert.
Het antwoord op de vraag ‘waarom zijn we niet rampenproof’ wordt beantwoord in de plaatjes ‘Interdepartementale samenwerkingrelaties gericht op het inperken en/of voorkomen van ……’, dat in nagenoeg ieder rapport staat. Neem die van ‘catastrofaal terrorisme’ eens, leuk plaatje en niet eens compleet overgenomen.
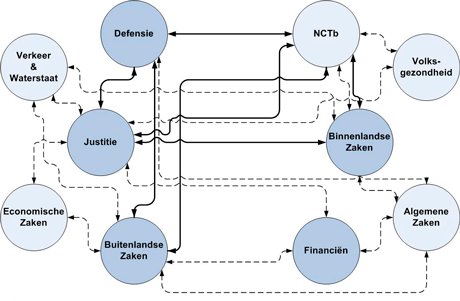
10 overheidspartijen zijn er druk mee bezig. 9 ministeries en de Nationaal Coördinator Terrorismebestrijding. Volgens de site www.nederlandtegenterrorisme.nl zijn 200.000 professionals dagelijks bezig om ons een veilig gevoel te geven. Bezig met informatie genereren, dubbel werk doen, langs- en tegen elkaar werken, veel communiceren etc. Het kost allemaal bijna niets, dat gevoel van schijnzekerheid.
Gegevens
Voor het besturen van het land zijn er zes authentieke basisregistraties: Personen, Gebouwen, Adressen, Bedrijven, Kaarten en Percelen. Het ministerie van VROM is verantwoordelijk voor vier van de zes authentieke basisregistraties, namelijk: Gebouwen, Adressen, Percelen en Kaarten. Het ministerie van Economische Zaken (EZ) is verantwoordelijk voor het Basis Bedrijven Register (BBR). Het ministerie van Binnenlandse Zaken en Koninkrijksrelaties (BZK) is verantwoordelijk voor de Basisregistratie Personen (de GBA). Daarnaast heeft het ministerie van BZK de verantwoordelijkheid voor het stelsel als geheel.
De overheid beschikt over veel gegevens die nodig zijn voor haar dienstverlening én voor het uitoefenen van controle, maar deze gegevens (die verder zijn verdeeld over circa dertigduizend landelijke, provinciale en gemeentelijke databanken) zijn als geheel onvoldoende accuraat en onvoldoende uitwisselbaar. Veel van deze bestanden zijn bovendien onvolledig, niet actueel of de gegevens zijn niet juist. Dus onbetrouwbaar. Ook komen forse verschillen in definities voor, waardoor dezelfde gegevens op verschillende wijzen worden vastgelegd. Daardoor zijn de bestanden moeilijk te koppelen en wordt veel tijd en geld verspild aan inefficiënt gegevensverkeer.
Voor nagenoeg iedere taak, proces, is er een applicatie voorhanden, geoptimaliseerd voor die specifieke taak, dat proces. Natuurlijk is ook de overheid bezig met het uitgeven van vermogens aan applicatie-integratie: het met elkaar laten samenwerken van los van elkaar ontwikkelde applicaties. Zeer kostbaar en op de traditionele manier lukt het nooit, ondanks het feit dat de traditionele automatiseerders hier SOA’s en dergelijke voor uitgevonden hebben. Het kan veel simpeler.
Het probleem van vandaag
Net zoals wij allemaal zit de overheid met het probleem van vandaag de dag dat er teveel data en te weinig informatie is. Op persoonlijke computers, op de netwerken van de ministeries en op het Internet. En allemaal ongestructureerd, niet verbonden, op circa 20% van de data op het netwerk van de organisatie na.
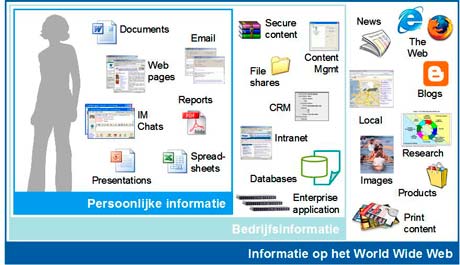
Onze terreur- en rampenbestrijders raadplegen iedere dag het Internet en tientallen databases, ieder via hun eigen gebruikers interface. Ze zijn de hele dag bezig om informatie uit tientallen, honderden, bronnen te halen en zijn specialist in lezen, knippen en plakken. Zijn ze tot een conclusie of vermoeden gekomen dan worden die in het rond gemaild en bij de vermoedens worden er tientallen mails met verzoeken om verdere informatie naar andere overheidsdiensten en terreurbestrijders in andere landen gestuurd. Waarna ze weer gaan lezen, knippen en plakken als de antwoorden binnenkomen etc. Al dat knippen en plakken komt de zuiverheid van de eindconclusie niet tegoede.
De juiste informatie op het juiste moment op de juiste plaats
De conclusie van de rapporten eist een efficiencyslag. De huidige werkwijze kost teveel tijd, er wordt teveel gemist en teveel onnodig werk gedaan. De juiste informatie moet op de juiste manier gepresenteerd, op het juiste moment aan de juiste mensen ter beschikking gesteld worden. En dat lukt niet, zo leren de rapporten, het is altijd te laat en te weinig. Toch kan het wel.
Politie
Je kunt zeggen wat je wilt, maar traditioneel een van de slechtst geautomatiseerde overheidsinstellingen, de politie, heeft de zaak anders aangepakt. Ooit 26 eilanden van informatie, ieder met hun eigen aanpak en systemen. Het Korps Landelijke Politie-diensten en de andere 25 politiekorpsen kunnen nu criminele informatie van andere korpsen ‘googelen’. BlueView heet het, een xml1 -database, regionaal gevoed en landelijk ontsloten.
Uit ergernis geboren want de uitwisseling van gegevens tussen de korpsen veroorzaakte die. Het duurde veel te lang voordat de juiste informatie bij de juiste persoon was. Een enorme stap vooruit. Voorheen ging alle informatie-uitwisseling via de telefoon of e-mail. Soms kostte het wel zesentwintig e-mails voordat iemand de opgevraagde informatie in zijn bezit had. Nu is het mogelijk om 55 miljoen documenten te bekijken. Het gaat om verhoren, aangiftes, gegevens van verdachten en bijvoorbeeld openstaande boetes.
Knap hoor, en bijna helemaal zelf in elkaar geknutseld. Er waren veel vergaderingen voor nodig en wat het precies gekost heeft is wat moeilijk te googelen. Daar heb je dat woord, googelen, volgens de Dikke van Dale het zoeken naar informatie op Internet. Een merknaam die een nieuw werkwoord opleverde. Een merk dat continue nieuwe diensten en mogelijkheden biedt, een merk dat blijft innoveren.
Google Search Appliance
Zou nou iemand bij de Politie Google gebeld hebben voordat ze met hun kostbare gefröbel en vergaderen begonnen zijn? Standaard te koop, zo van de plank, Google Search Appliance. Dankzij de Google OneBox voor bedrijven realtime bedrijfsinformatie, bovenop de zoekresultaten, van bedrijfsapplicaties, ondersteuning van meer dan 200 bestandstypes etc.
Veiligheid
‘Google is natuurlijk niet veilig genoeg voor de Politie, terreur- en rampenbestrijders.’ Niet waar, de bestaande beveiliging- en toegangcontrolesystemen worden gebruikt. En die zijn, natuurlijk, helemaal top binnen de overheid. Zijn ze dat niet, dan kan Google wel helpen, ze hebben net voor $ 625 miljoen beveiligingsfabrikant Postini gekocht.
Google Glut
Vroeger Info Glut, je krijgt gewoon teveel informatie terug van een zoekopdracht. En alles waar ‘te’ voorstaat is niet goed, behalve tevreden. Waar, absoluut een punt, je krijgt simpelweg teveel informatie terug. PageRank™ of geen of geen PageRank™.
De mens kan informatie verwerken omdat hij er betekenis aan toevoegt. Die betekenis haalt hij uit de context, uit de relatie met gebeurtenissen en informatie uit het verleden. De informatie “onbekend virus legt half Nederland plat” heeft bijvoorbeeld in een medisch tijdschrift een andere betekenis dan in een computer tijdschrift. Google biedt geen ondersteuning om de betekenis van data te managen. Een ernstige tekortkoming.
Topic Maps
Maar, dat kan je oplossen door kennistechnologie in te zetten, bovenop Google, dan ben je in staat de betekenis van informatie managen. Zoek je in de encyclopedie betekenis op, dan vindt je: ‘Betekenisleer, z Semantiek’. Ga je naar semantiek, dan vindt je: ‘Semantiek’ (v. Gr. sèma = teken) of betekenisleer, de naam van de wetenschap die zich bezighoudt met de betekenis van woorden.’
Enfin, laten we het kort houden. Een woordenboek geeft de betekenis van alle data, een encyclopedie geeft de verklaring van alle data en URL’s2 geven de vindplaatsen van alle data.
Het paradigma Topic Maps is een open ISO3 standaard voor kennisintegratie en is ook de enige internationale standaard voor kennisintegratie.
Topic Maps is ook een webstandaard én een data model met een XML uitwisselingssyntax. Hiernaast is er nog een hele Topic Maps standaarden familie maar er zijn ook aanverwante standaarden. De standaard wordt wereldwijd gedefinieerd, steunt op het idee van de index in een boek, maar dan meer dynamisch, en zorgt zo dat informatie tussen systemen gemakkelijk is te verbinden, uit te wisselen en terug te vinden.
Topic Maps gebruikt de betekenis, de verklaring en de vindplaatsen om data te verbinden en er binnen te kunnen navigeren. Dàt door middel van veel technologie, metadata, taxonomieën, ontologieën én Topics, Associations en Occurrences, die alle drie ook nog getypeerd kunnen worden aan de hand van Topics, zodat al snel een netwerk van entiteiten met betekenisvolle onderlinge relaties ontstaat.
Met Topic Maps kan men:
• Zeer grote informatiebronnen organiseren;
• Gemeenschappelijke kennis vangen en delen;
• Complexe regels en processen representeren;
• Onderwerp gebaseerd presenteren;
• Gedistribueerde kennis en informatie beheersen;
• Informatie en kennis aggregeren.
Maar goed, als u in de technologie geïnteresseerd bent, zie voetnoot4 .
Voorbeeld
Zoals gezegd, we barsten van de semi-gestructureerde data in tienduizenden bronnen. Hoe die bij elkaar te krijgen in één beveiligde omgeving. Wel, we beginnen met de aanschaf van het Google Search Appliance model GB-8008, die heeft een onbeperkte capaciteit. De installatie duurt zeker wel een uurtje, het vergaderen over welke bronnen we willen hebben en toestemming te krijgen om Googlebot, Google’s web crawling robot te sturen, vergt waarschijnlijk wat meer tijd. Als dat voor elkaar is sturen we Googlebot en die haalt, keurig, via beveiligde verbindingen, normaal 1× per 24 uur, alle data op. Google’s One-Box for Enterprise zorgt ervoor dat databases, gestructureerde data, real-time, beschikbaar zijn.
Zodra Googlebot de data binnen heeft, geeft hij die, de volledige tekst van alles wat hij gevonden heeft, over aan Google’s indexer. Die indexeert, sorteert en verbindt aan ieder woord een lijst met de documenten waarin de term voorkomt en waar de term in het document voorkomt. Zoals de index achter in een boek, maar dan wel een index waarin ieder woord in het boek is opgenomen. De oorzaak van Info Glut. Correctie: om de performance te verhogen indexeert Google’s indexer stopwoorden, zoals de, is, of, hoe en enkele letters niet. Alles, ieder woord, teken en bedrag, wordt keurig opgeslagen in XML. Met daarbij veel informatie over de data.
Daarna gaat het geheim van Google, Google’s Query Processor, aan het werk. Maar ja, dat is geheim, in ieder geval het algoritme dat de PageRank bepaalt. Meer dan 63 componenten van PageRank, van de > 100, zijn door patenten beschermd. Er wordt ook veel artificiële intelligentie gebruikt om relaties en associaties in de opgeslagen informatie te leggen, analyseren. De spellingcorrectie algoritmes, ‘Bedoelt u:’ maken daar veel gebruik van. Wat ook geheim is zijn het aantal servers en de plaats waar ze staan. In ieder geval zijn het > 300.000 servers. Maar er staan dan ook > 8 miljard webpagina’s, > 880 miljoen afbeeldingen en > 845 miljoen Usenet-berichten op. De Google-interface ondersteunt > 100 talen en daarvan worden er 35 door de zoekresultaten ondersteund.
Unified View
We hebben de data. Met Topic Maps ‘lijmen’ we de data aan elkaar tot informatie. Waarna we vragen kunnen stellen als: ‘Geef mij de namen van alle nog levende vaders van statutaire bestuurders van ondernemingen in de provincie Limburg’. Of, ‘geef mij de kentekens van alle auto’s die volgende week een APK-keuring moeten ondergaan en die niet verzekerd zijn’. En daar krijgen we dan keurig antwoord op.
Met Topic Maps kan data verbonden worden tot informatie en kan de kennis van een organisatie vastlegt worden in een kennislaag. Dat is belangrijk want, hoe meer onze computers verbonden zijn, hoe meer we ons realiseren hoe onsamenhangend onze informatie is. En onsamenhangende informatie kost geld. Verspreid over meerdere systemen wordt het moeilijker om te vinden. Verdubbeld over verschillende afdelingen, veroorzaakt het overtolligheid en wordt het onbetrouwbaar. Geïsoleerd in informatie opslagplaatsen die niet met elkaar communiceren, faalt het in het bereiken van haar volle waarde.
Onsamenhangende informatie betekent onsamenhangende kennis. Kennis die niet gedeeld kan worden. Inzichten die niet getrokken kunnen worden. En beslissingen die niet gemaakt kunnen worden. Omdat de juiste informatie niet beschikbaar was bij de juiste mensen op het juiste tijdstip.
Who will guard the Guardians?
Google in combinatie met Topic Maps is kennis en dus macht. Plato vroeg het zich bijna 2.500 jaar geleden al af in zijn ‘The Republic’: ‘Who will guard the Guardians?’ Kennis is macht én zoals John E.E.D. Acton, of Lord Acton (1834-1902), opmerkte, ‘Power tends to corrupt, and absolute power corrupts absolutely.’
Maar wil je de maatschappij beschermen tegen terrorisme en criminaliteit, dan heb je informatie, kennis, nodig. Uit onderzoek van het Nationaal Comité 4 en 5 mei blijkt dat 71 procent van de Nederlandse bevolking veiligheid verkiest boven privacy. Binnen de overheid is de (optimistische) norm dat 75% van de mensen zich aan de regels houdt, 20% calculeert en 5% fraudeert. Als er een referendum over gehouden wordt, dan zal de meerderheid van de Nederlandse bevolking dus wel voor stemmen, áls het goed geregeld wordt.
Zowel Google als Topic Maps hebben alles in zich om het goed te regelen. Met Topic Maps kan je diverse ‘views’ op dezelfde data genereren. Dus de politieagent mag dat zien, de Officier van Justitie alles etc. Omdat Google bij iedere zoekopdracht ‘snippets’ achterlaat, is er in accountantstaal een ‘audit trail’. Wie heeft wat gezocht, wat je kunt uitbreiden met, mét welk autorisatie etc. Technisch geen probleem en onze democratie is wel zo ingericht dat we in ieder geval een kader hebben om misbruik van macht tegen te gaan.
Nederland is geen eiland
Wat wij hier ook willen, wij zijn niet alleen op deze wereld. De Amerikanen hebben onder hun Homeland Security Act nagenoeg onbeperkte bevoegdheden om informatie te verzamelen. Niet alleen hebben zij alle gegevens van het internationale betalingsverkeer via SWIFT, ook alle passagiergegevens van vluchten naar of over Amerika ontvangen zij. En bewaren zij 15 jaar lang. Maar de bevoegdheid gaat veel verder, ze kunnen bij de data komen van alle computers die eigendom zijn van Amerikaanse bedrijven en organisaties. Ook al staan deze computers buiten de Verenigde Staten. Dus uw creditcardgegevens, etc. zijn ook bekend bij de Amerikanen.
Daarnaast heeft onze maatschappij dringend behoefte aan juiste informatie over mensen en bedrijven. De banken moeten hun klant kennen, Know Your Customer (KYC) etc. Wat doen ze, ze vragen een kopie van je identiteitsbewijs en raadplegen verder het BKR, de Kamer van Koophandel etc. Is het niet beter om de, alle, informatie, gecontroleerd, van overheidswege te verstrekken. Dan kan je als burger zelf, via je DigID, ook nog eens controleren of het klopt, wat ze allemaal over je zeggen. Klopt het niet, dan ga je naar het BKR, de Gemeente (GBA), het Kadaster etc. om de informatie te laten corrigeren. De informatie is er toch en ze wordt gebruikt. Beter de juiste gegevens dan verkeerde gegevens waarvan je niet weet waar ze vandaan komen.
Robert Stamsnijder, HHM Holding, R.Stamsnijder@Planet.nl
Voetnoten.
1 eXtensible Markup Language, een standaard die vaak wordt genoemd sinds de start van het World Wide Web. XML is een krachtig medium voor het beschrijven, communiceren en implementeren van informatie management. XML is een data formaat om data te organiseren. Wat XML niet doet is inzicht geven hoe informatiebronnen met elkaar zijn gerelateerd. Om inzicht geven hoe informatiebronnen met elkaar zijn gerelateerd (en dus data te kunnen verbinden) zijn er 2 andere standaarden: Resource Description Framework (RDF) en Topic Maps.
2 Een Uniform Resource Locator (afgekort URL, ook wel IRI, URN, URL, http:URI, XRI, WPN, TDB, … etc.) is een label dat verwijst naar een informatiebron, bijvoorbeeld een webpagina, een bestand of een plaatje op internet.
3 De Topic Maps standaard is gepubliceerd als ISO-standaard, in 2000 als ISO/IEC 13250:2000, later in 2001 is ‘the XML Topic Maps (XTM) Specification’ gepubliceerd om Topic Maps ook kunnen te gebruiken op het web. XTM bevat een abstract model en een XML grammatica om web-gebaseerde Topic Maps uit te wisselen. Andere Topic Maps gerelateerde standaarden zijn de ‘Topic Maps Query Language’ specificatie en de ‘Topic Maps Constraint Language’.
4 – Het concept Topic Maps wordt helder uitgelegd in het artikel The TAO of Topic Maps – Steve Pepper – Ontopia
- Technisch rapport en verwijzingen Topic Maps – Robin Cover – OASIS
- De gids naar Topic Maps standaardisatie – WG3 sc34 – ISO
- Handleidingen, leveranciers en bronnen – topicmap.com
- Verwijzingen naar tools en software – topicmap.com
Plaats als eerste een reactie
U moet ingelogd zijn om een reactie te kunnen plaatsen.