

Data science en datagedreven sturing: hoe pak je dit aan?
Data science en datagedreven sturing: hoe pak je dit aan?
Data science en datagedreven beslissingen nemen. Je krijgt het steeds vaker mee in de media, hoort het op symposia, ziet bedrijven er reclame voor maken en leest over ambities in de publieke sector over datagedreven sturing. Kort door de bocht houdt data science in dat je oplossingen zoekt voor problemen, door verbanden te zoeken in bestaande data, misschien wel met een heel ander doel dan waarvoor de data oorspronkelijk verzameld zijn. Bekende toepassingen van data science zijn het vergroten van inzicht in bedrijfseconomische processen (bijvoorbeeld de identificatie van risicovolle klanten) en het optimaliseren van logistieke processen (zoals het verkorten van de doorlooptijd van een productieproces). Data science kan echter ook gebruikt worden om te voorspellen waar de meeste inbraken zullen worden gepleegd of welk deel van de stad de grootste kans heeft op een brand (tot op het uur nauwkeurig). Hierop kan dan de inzet van politie en brandweer worden afgestemd.
Data science en datagedreven sturing laten daarmee een enorm potentieel zien: het verbeteren van de samenleving met data die er ‘gewoon’ al zijn. Op het eerste gezicht een kwestie van datasets verzamelen, koppelen en statistische trucjes uithalen, toch? Helaas is dat in de praktijk vaak niet zo eenvoudig als het op het eerste gezicht lijkt. Het inzetten van data science is vooral een proces van trial-and-error. In dit artikel gaan we in op enkele voorname valkuilen en kansen die horen bij de inzet van datagedreven sturing in de publieke sector. Het belangrijkste uitgangspunt is daarbij het inrichten van een passende projectorganisatie: succesvolle implementatie van data science is in de eerste plaats een succesvol project. Dit uitgangspunt zorgt ervoor dat de inzet van data science leidt tot echte impact voor de klant of maatschappij. Onze aanbeveling: focus eerst op de goede organisatie van het project, de specifieke technieken en tools volgen later wel.
Data science volgt geen klip-en-klare route naar resultaten
Sinds enkele jaren is I&O Research intensief aan de slag met data science met een gespecialiseerd, multidisciplinair team. Dit team zoekt antwoorden op beleids- en onderzoeksvragen die leven in de publieke sector door gebruik te maken van data science-methoden en -technieken. De organisatie van een data science-project verschilt namelijk op verschillende punten van gangbare onderzoeken.
De meeste onderzoeken volgen een relatief overzichtelijke route. Hierbij is vooraf nagedacht over een onderzoeksvraag die moet worden beantwoord en er wordt een plan opgesteld om begrippen en concepten te meten. Vaak gebeurt dit door middel van een vragenlijst of een gespreksleidraad die op maat gesneden is. Tot slot worden de resultaten veelal gepresenteerd in rapporten, factsheets of dashboards. Tijdens het onderzoek zal er nog wel wat bijgestuurd moeten worden, maar hoe het eindresultaat eruit zal zien, is bij aanvang van het project al wel in grote lijnen duidelijk.
Bij een data science-project is dit lang niet altijd het geval. Ten eerste is de precieze onderzoeksvraag vooraf niet altijd duidelijk en ten tweede bestaat er vaak nog geen concreet idee van het gewenste eindproduct. Het is niet ongewoon dat een data science-project een spin-off is van een ander onderzoek. Een onderzoek voor een verzekeringsmaatschappij kan bijvoorbeeld waardevolle input voor de brandweer opleveren om de inzet van mensen en materieel af te stemmen op het verwachte aantal branden in een wijk. Het data science-project van de brandweer komt in dit voorbeeld niet voort uit de vraag om de inzet van de brandweer te optimaliseren. Het is een bijproduct van het eerdere onderzoek voor de verzekeringsmaatschappij.
Een ander verschil met traditioneel onderzoek is de variëteit aan data: van gestructureerde gegevensbestanden met rijen en kolommen tot ongefilterde, ongelijksoortige data, zoals tekst, audiomateriaal en sensordata. Tabel 1 vat de belangrijkste verschillen tussen traditioneel onderzoek en data science-onderzoek samen.
Tabel 1 Overzicht van traditioneel onderzoek vs. data science-onderzoek
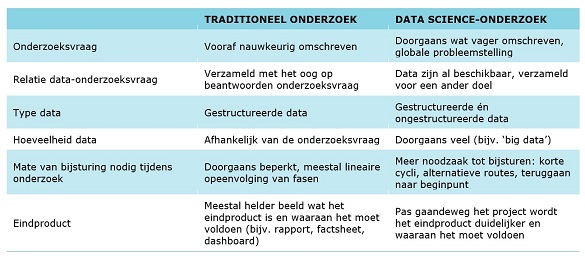
Zoals uit tabel 1 naar voren komt, zijn er bij data science enkele inhoudelijke en procesmatige risico’s. Behalve het einddoel dat niet altijd duidelijk is, kun je ook te maken krijgen met data die niet beschikbaar of gebruiksklaar zijn, een (te) grote hoeveelheid data, trage voortgang in het project en een te nauwe blik op de dataset en de resultaten. Hieronder volgt een korte beschrijving van deze valkuilen en een manier waarop de projectorganisatie zo ingericht kan worden, dat deze risico’s zo veel mogelijk beperkt worden.
Het verkrijgen van data: zorg voor commitment in de organisatie
Zeker als het gaat om informatie op individueel niveau heeft een data scientist niet direct toegang tot de data en is hulp van derden in of buiten de organisatie noodzakelijk. De persoon of het team dat met een project aan de slag gaat, moet dus zorgen voor het benodigde commitment in een organisatie om het project verder te helpen. Dit kan dusdanig veel werk zijn, dat er een aparte rol in het projectteam moet worden gecreëerd. Een bijkomstig probleem is dat data niet altijd te koppelen zijn, bijvoorbeeld omdat een koppel- of sleutelvariabele ontbreekt. Een quick-scan zorgt ervoor dat er in een vroegtijdig stadium meer zicht is op de complexiteit van de aanwezige data en welke aanvullende bewerkingen nodig zijn.
Gebruiksklaar krijgen van data: voorkom ‘information overload’
Information overload is een reëel risico. Door de grote hoeveelheid data en het brede pallet aan verschillende technieken, bestaat er de kans dat je het overzicht verliest. Om dit te voorkomen is het belangrijk dat je altijd de focus op het onderzoeksdoel houdt. Binnen het team moet iemand de regie houden en de belangrijkste mijlpalen bewaken. Dit vraagt om heldere afspraken met de klant, waarin de consequenties van bepaalde keuzes voor de aanpak, planning en het eindresultaat worden geschetst.
Zorg voor voortgang in het project: richt projectorganisatie in op wijzigingen en onzekerheden
De data scientist zal in veel gevallen niet bij het verzamelen van de data betrokken zijn geweest. Hij of zij heeft dus te maken met secundaire gegevens. Bij het bewerken, analyseren en interpreteren van secundaire data is het aannemelijk dat dingen niet lopen zoals vooraf gedacht. Voor een succesvol data science-project is het daarom belangrijk om te werken met een multidisciplinair team, eventueel gecombineerd met de scrum-methodiek.
Suggestie 1: denk én werk multidisciplinair
Het is belangrijk dat drie facetten van data science worden afgedekt: (1) kennis van het domein of werkveld, (2) kennis van (statistische) methoden en technieken en (3) ICT-vaardigheden, bijvoorbeeld om data te ontsluiten. Met een multidisciplinair projectteam kan er vanuit meerdere invalshoeken naar de voortgang worden gekeken. Denk hierbij aan een mix van data scientists, teamleiders, ICT’ers, methodologen, beleidsmedewerkers en/of uitvoerende medewerkers. Door het ‘probleem’ te bekijken vanuit verschillende achtergronden voorkom je tunnelvisie. Door teamleiders en managers erbij te betrekken, vergroot je de kans dat het traject leidt tot relevante (en gedragen) inzichten waarmee de organisatie aan de slag kan. Bovendien moet een data science-project natuurlijk niet beperkt blijven tot een leuk tijdverdrijf. Echte impact voor de organisatie moet vooropstaan!
Suggestie 2: gebruik de scrum-methodiek
Onze tweede suggestie: gebruik de scrum-methodiek. Deze methodiek houdt in dat een project wordt uitgevoerd in korte etappes of ‘sprints’. Na een gezamenlijke aftrap van het project wordt in korte rondes gewerkt aan kleine deeltaken. De uitkomsten hiervan worden steeds tussentijds met het team geëvalueerd. Werkt een mogelijke oplossing niet? Geen probleem, ga terug naar het startpunt en verken een andere route. Door te werken met korte sprints is het mogelijk om snel te schakelen in een project en tegelijk het overzicht te bewaren.
Eigen ervaringen met data science
Sinds de oprichting van het team Data Science is I&O Research voor verschillende opdrachtgevers aan de slag gegaan. Behalve interne projecten waarbij wij gebruikmaken van eigen en openbare datasets ondersteunen we onder meer de gemeente Apeldoorn en andere gemeenten in Nederland. Verder hebben wij in opdracht van het ministerie van Binnenlandse Zaken en Koninkrijksrelaties data science-onderzoek uitgevoerd voor het kennisproduct de Staat van het Bestuur 2018.
Tijdens dit onderzoek hebben wij de data en resultaten toegankelijk weergegeven in verschillende interactieve infographics.
Voorzieningengebruik Nederlandse gemeenten
Bij één van de interne projecten die wij hebben uitgevoerd, hebben wij gekeken naar verklarende factoren voor het voorzieningengebruik in Nederlandse gemeenten. Er is een model ontwikkeld dat voorzieningengebruik in regionaal perspectief plaatst en verklaart waarom het voorzieningengebruik in sommige gemeenten hoger is dan in andere. Hiervoor zijn ook variabelen uit een eerder onderzoek van het Sociaal en Cultureel Planbureau (SCP) gebruikt. Uit deze analyse blijkt dat vooral sociaaleconomische variabelen van invloed zijn op het voorzieningengebruik. Dit komt overeen met de conclusies van het SCP. Verder is in dit project een waardevolle, omvangrijke gemeentelijke database ontwikkeld die we bij vervolgprojecten kunnen inzetten.
Het staat buiten kijf dat data science – met de juiste mix van expertise, flexibele projectskills en input van stakeholders - veel kansen biedt om voor maatschappelijke vraagstukken extra, nieuwe inzichten te verwerven.
Meer informatie
- Leon Heuzels | l.heuzels@ioresearch.nl | 053 20 05 252
- Laurens Klein Kranenburg | l.kleinkranenburg@ioresearch.nl | 053-200 52 22
1081 JK Amsterdam
Ipsos I&O: Peilpraat
Bekijk hier Peilpraat 24 oktober. Standpunt over religieuze scholen kost CDA zetels, D66 profiteert. Bekijk hier Peilpraat oktober. Verschuivingen na RTL-debat. Bekijk hier Peilpraat september: Wat vinden kiezers van uitsluiten? Bekijk hier Peilpraat mei: Is er toekomst voor NSC? Bekijk hier Peilpraat april: Tevredenheid met kabinet op dieptepunt, welke alternatieven zien kiezers? Bekijk hier Peilpraat maart: Hoe internationale spanningen de Nederlandse politiek beinvloeden. Bekijk hier Peilpraat februari: De hardwerkende Nederlander en potentie voor nieuwe linkse partij.

Het dilemma van de ambtenaar: tegenkracht of tegenmacht?
Bekijk hier de video.

Veiligheidsmonitor
Ipsos I&O: Peilpraat
Bekijk hier Peilpraat 24 oktober. Standpunt over religieuze scholen kost CDA zetels, D66 profiteert. Bekijk hier Peilpraat oktober. Verschuivingen na RTL-debat. Bekijk hier Peilpraat september: Wat vinden kiezers van uitsluiten? Bekijk hier Peilpraat mei: Is er toekomst voor NSC? Bekijk hier Peilpraat april: Tevredenheid met kabinet op dieptepunt, welke alternatieven zien kiezers? Bekijk hier Peilpraat maart: Hoe internationale spanningen de Nederlandse politiek beinvloeden. Bekijk hier Peilpraat februari: De hardwerkende Nederlander en potentie voor nieuwe linkse partij.